Las siglas CAPTCHA significan "Completely Automated Public Turing test to tell Computers and Humans Apart", lo que podría traducirse en algo así como "Test de Turing público y automático para distinguir a los dispositivos de los humanos". Esta prueba fue inventada en 2003 por Luis von Ahn, un matemático guatemalteco, y se convirtió en una herramienta fundamental para proteger los sitios web del ataque de bots.
Sobre su inventor

Como empresario del mundo de la informática, Von Ahn fundó, además de CAPTCHA y reCAPTCHA, la aplicación para aprender idiomas Duolingo, y es considerado uno de los pioneros de la idea de crowdsourcing, que consiste en externalizar tareas que, tradicionalmente, realizaban empleados o contratistas, dejándolas a cargo de un grupo numeroso de personas o de una comunidad, a través de una convocatoria abierta. En el año 2009, vendió reCAPTCHA a Google.
Evolución de los CAPTCHA
Los primeros CAPTCHA consistían en identificar palabras distorsionadas que los programas informáticos no podían reconocer. Con el tiempo, la tecnología evolucionó y los CAPTCHA se volvieron más complejos, incluyendo imágenes, rompecabezas y análisis de comportamiento. La última generación de CAPTCHA, como reCAPTCHA de Google, utiliza inteligencia artificial para diferenciar entre humanos y bots de forma aún más precisa.
Una curiosidad sobre su historia fue compartida en un conversatorio virtual de la Universidad de San Martín, titulado "El impacto de los Argoritmos en la vida cotidiana". Quien habló ahí fue Esteban Magnani, autor del libro La jaula del confort —que realiza un análisis sociológico sobre la informática y la distribución de nuestros datos—y ensayista en la revista Anfibia.
Analizando la idea de crowdsourcing, comenta que Von Ahn consideró todas las miles de horas que pasabámos (o desperciciabámos) las personas alrededor del mundo completando CAPTCHA. Para ello, desarrolló una solución en la que los CAPTCHA servirían para digitalizar libros: cuando una palabra no se veía muy clara, se la ponía en esta prueba. Si muchas personas coincidían en una respuesta, se corregía en el archivo del libro o texto.
Esta solución se volvió obsoleta a partir del año 2017, cuando se desarrollaron sistemas sistemas software basados en inteligencia artificial que conseguían resolverlos fácilmente.
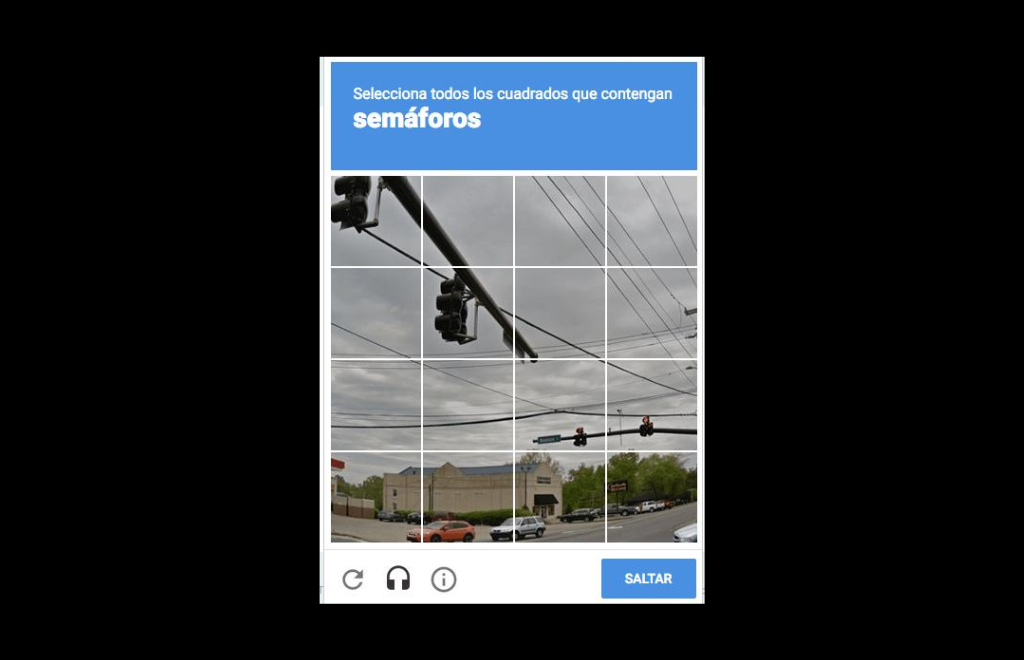
Por eso, aparecieron los CAPTCHA de reconocimiento de imágenes, que mejoraban su accesibilidad y eran eficaces ya que los robots carecían de la capacidad para entender e interpretar imágenes. Sin embargo, la aparición de algoritmos de reconocimiento de imágenes puso en peligro su efectividad.
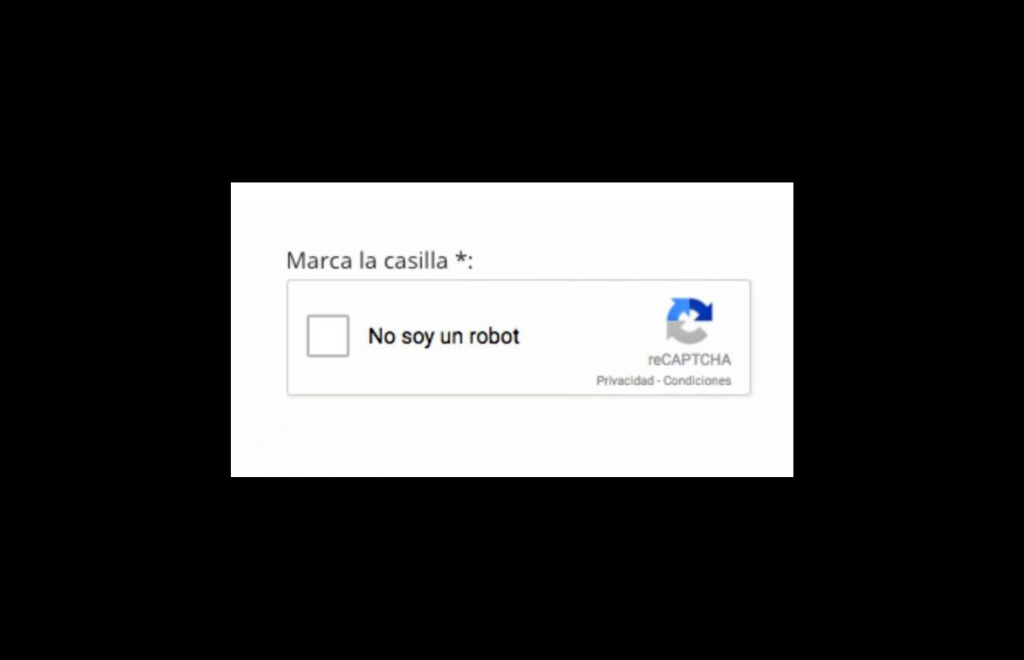
Aunque hoy en día existen varios tipos de CAPTCHA, uno de los comunes es en el que simplemente debemos tildar o clickear en la opción "no soy un robot". El desafío para los robots no es que no puedan clickear en esa opción, sino que la prueba leé el movimiento de nuestro mouse hacia la cajita. Al ser humano, el movimiento tiende a ser menos predecible y no va en líneas perfectamente rectas. Si bien este tipo de desafío no tiene una dimensión productiva, tampoco hace que los usuarios perdamos tiempo.
CAPTCHA en la actualidad y en el futuro
Los CAPTCHA son esenciales para proteger los sitios web de una amplia gama de amenazas, como el spam, el robo de datos, el abuso de formularios y los ataques de denegación de servicio. Sin ellos, los bots podrían acceder a información confidencial, realizar acciones no deseadas y, en general, degradar la experiencia de los usuarios legítimos.
Como vimos, estas pruebas se ven constantemente amenazadas por nuestros avances en cuanto a tecnología, inteligencia artitficial, bots y automatizaciones. Por eso, deben evolucionar a la par e implican que haya constante investigación para proteger nuestros datos y ciberseguridad sin empobrecer nuestra experiencia en la web.